01
Switch models, keep the thread
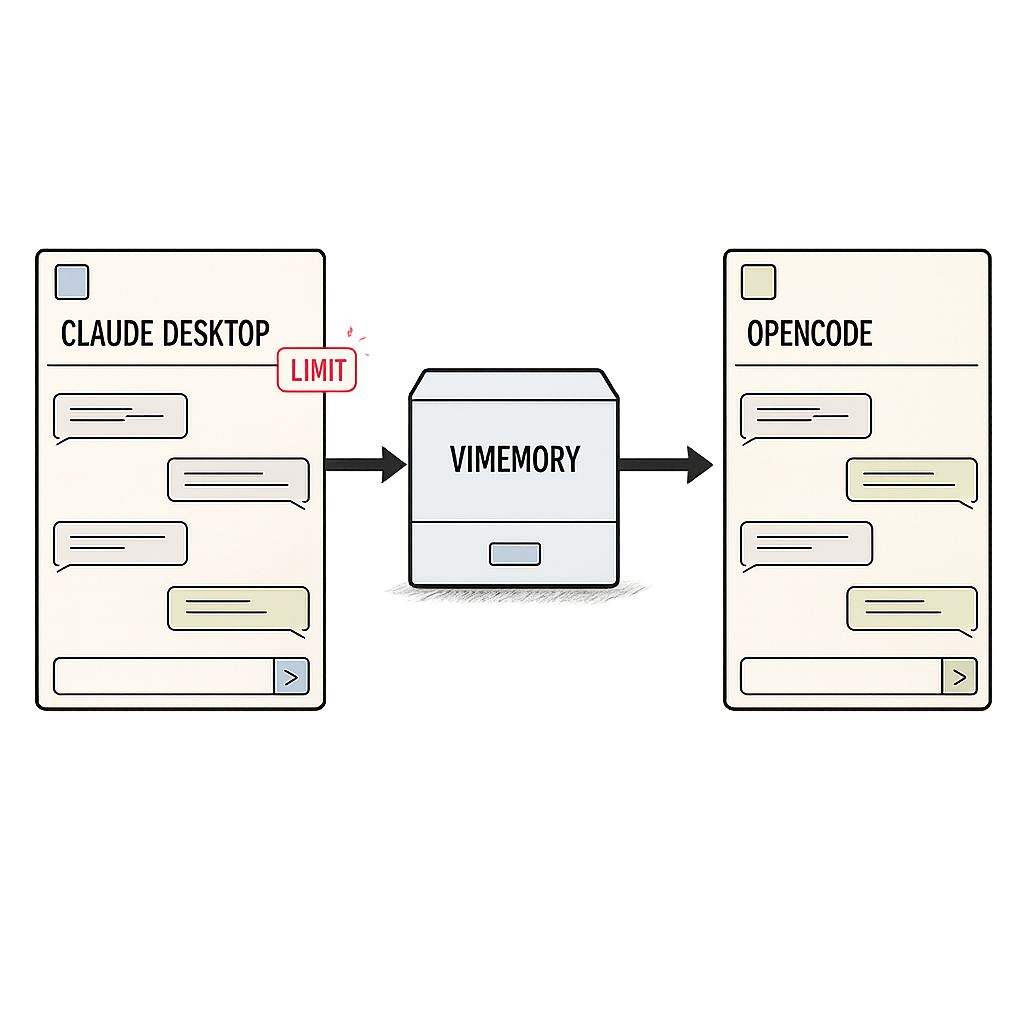
Save in Claude. Recall in opencode, ChatGPT, DeepSeek, Gemma — whatever you run. No re-pasting, no re-explaining. The limit stops the chat, not the work.
Memory for multi-model teams
One private memory every AI model reads from. Hit a limit, switch to any other model or platform, and pick up exactly where you stopped. Self-hosted. Beta. Honest.
Five real limitations, stated plainly. If any of these is a dealbreaker, this product isn't for you — and that's fine.
Still here? Good. Now the part where it actually helps.
Save in Claude. Recall in opencode, ChatGPT, DeepSeek, Gemma — whatever you run. No re-pasting, no re-explaining. The limit stops the chat, not the work.
Each teammate gets an isolated namespace. You can't read theirs, they can't read yours. Isolation is enforced, not promised.
"Harga" finds "pricing." It matches on meaning, not exact words — so recall works even when you phrase it differently.
Self-hosted on your own box. No third party holds your team's memory. You keep the keys, literally.
Tell your AI: "save this to my memory." It summarizes and stores it. One line, done.
Out of Claude credits? Move to opencode or whatever you run. Your memory is already there.
Ask the new model. It pulls the relevant context by meaning and picks up where you stopped.
No black box. Here's exactly what runs and why each piece is there. If a term's new to you, the plain-English bit after it is the part that matters.
On price: we haven't set one. It's a beta — early teams get in free while we figure out if this is worth charging for. If and when there's a price, you hear it from us first. No surprise invoice.
Open the waitlist form →Opens our Notion form in a new tab. We onboard a few teams at a time, personally — that's not scarcity marketing, it's a small team being honest about capacity.